With YAPI it is possible to create hierarchical process networks. A hierarchical network is a network that contains other process networks. The purpose of such a hierarchy is to raise the level of reuse from processes to process networks. A process network is also an abstraction of some functionality, similar to a process. This abstraction hides information which is essential for managing the complexity.
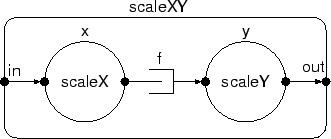
To be able to use a process network as a component within another network, the process network must have ports to let it communicate with its environment. Here, we present an example of such a process network that can be used as a component within another network. The process network scales pictures in the horizontal and vertical direction. The process network has two ports, in and out, two sub-processes, x and y, and an internal fifo channel f.
The network structure is created by the constructor, which first initializes the ports, then the internal fifos and finally the internal processes. In this network, the input port of the horizontal scaler is connected to the process network input port, in. The output port of the vertical scaler is connected to the output port of the process network, out. The output port of the horizontal scaler and the input port of the vertical scaler are connected to the internal fifo of the process network. As this example shows, the ports of the internal processes (and internal process networks) can be connected to internal fifos, or to the ports of the process network. The ports of the process network will be connected to external fifos, or the network ports of the surrounding network. There is no limit to the nesting of process networks.
|
|
It is important to note that the order in which the constructors of the ports, fifos, and processes are called is the same as the order in which they are declared in the header file. Therefore, always declare ports first, fifos next, and processes and process networks last. If you do not to comply to this rule, then the connection between ports and fifos may fail which causes unexpected behavior. Furthermore, note that you do not directly connect the input (output) of process x (y) to variable i (o), since you are then bypassing the ports of the process network. Therefore, always connect processes and process networks to member variables (ports and fifos) only.
As we saw earlier, process networks can be hierarchical. In fact, all YAPI objects, such as processes, ports, fifos, and process networks are part of a network hierarchy. In such a hierarchy every object, except the root process network, has a parent object. The parent of a port is a process or a process network. The parent of a fifo, the parent of a process, and the parent of a process network is a process network. The class Id has been introduced to identify the objects in the hierarchy, and to be able to retrieve information about these objects at run-time. This information may be used for many purposes, such as debugging.
The class Id provides the member functions parent, name, and fullName, to obtain the parent object, the name, and the full name of the object, respectively. The name of an object refers to the instance name of the object, represented by a null-terminated character string. The full name of an object is a representation of the complete path of the object in the network hierarchy. The full name is constructed by concatenating the names of the objects on the path starting at the root network, separated by dots. For example, the full name of output port out in process producer in process network pc is pc.producer.out. We recommend that you make the full names of objects unique, however this is not mandatory.
The classes ProcessNetwork, Process, Fifo, InPort, and Outport are derived from class Id, and thus the identification is supported for all these classes. In addition the classes ProcessNetwork and Process have a member function type which returns the class name of the object, represented by a null-terminated character string. The type is a property of the class, and is thus identical for every instance of a class
Programs Program 2.1.5 and Program 2.1.7 show examples of the usage of the member functions fullName and type, to print information about the producer and consumer processes before they terminate. The output of this example is as follows.
Consumer started Producer started Producer pc.producer: 1000 values written. Consumer pc.consumer: 1000 values read. |
The identification of an object is set via the first argument of its constructor. In the implementation of the constructor, the Id is passed to the constructor of the base class. In the constructor also the identification of the member objects must be set. In case of a process these are the input and output ports. Setting the Id of the member objects is done in the same way, namely via the first argument of the constructor. To ease the creation of an Id for the members, the member function id is available. This function takes a name as an argument and creates an Id with this name, and the current object as a parent. This Id is then passed to the constructor of the member object.
Identification is mandatory for all ports, fifos, processes and process networks. The implementation of the type function is also mandatory. This member function is a pure virtual function which will generate a compile error if the implementation is omitted.
read(p, x) |
This statement reads a value from input port p and stores this value in variable x. The syntax for writing values is:
write(q, y) |
This statement writes the value of variable y to output port q.
In YAPI, channels are strictly typed, i.e., one can only communicate one type of value via a fifo. In both the read and the write statement the type of the port must be identical to the type of the fifo and to the type of the variable.
read(p, X, m) |
This statement reads m values from input port p and stores these values consecutively in array X in array elements X[0] up to X[m-1]. The syntax for writing an array of values is:
write(q, Y, n) |
This statement writes n consecutive values of array Y from array elements Y[0] up to Y[n-1] to output port q. In vector read and write statements the type of the port must be identical to the type of the array element. For instance, if the ports are of type integer then X and Y must be arrays of integers. Note that the number of communicated values does not have to be known at compile-time, i.e., the value of variables m and n is determined at run-time.
To illustrate the use of vector read and write operations, we modify the Producer-Consumer example. First we introduce a vector write operation in the producer. To this end, we introduce an array Y of size n to which we assign the values that are to be written with a vector write operation.
|
|
Similarly, we introduce a vector read operation in the consumer. To this end, we introduce an array X of size n. Note that the value of n is not known to the consumer at compile time. Therefore, we allocate and free memory space at run time using the new and delete operations.
|
|
Note that the vector implementation of the producer (consumer) can be combined with the scalar implementation of the consumer (producer), since the interfaces of the processes have not changed. Only their internal implementations have changed. For example, the producer can be vector based having internally an array variable, while the consumer can be scalar based having internally a single variable. Hence, this example shows the purpose of the vector read and write operations, that is, to enable the decoupling of the data structures of the processes without introducing the need for additional read and/or write function calls.
Furthermore, note that it is up to the actual implementation of the vector read and write operations how the n consecutive values are communicated. For instance, when the room in the fifo is sufficient, the vector write may copy all values in one burst. Only if there is insufficient room in the fifo (e.g. when small fifos are used), the communication will take place at the smaller grain size, but this is hidden from the application designer.
The process networks we discussed so far are deterministic, i.e., for given input they produce the same output, independent of how the execution of the processes is scheduled. This property allows the application designer to plug a process or process network into an application and to execute it without the concern of scheduling the processes. However, there are applications, for instance interactive applications, that are not deterministic. To be able to model these applications as process networks, we introduce the synchronization operation select. The purpose of the select operation is to synchronize the calling process with non-deterministic neighboring processes.
A process that calls a select operation synchronizes with another process when the other process has committed to communicate the number of tokens requested by the calling process. In general, a select operation can take an arbitrary number of ports as arguments. With each port we associate a positive integer argument that indicates that the port must be willing to communicate that number of tokens in order to be a candidate for selection. This number is called the requested number of tokens. The default value for the requested number is one. Optionally, one can specify other values but in that case these values have to be specified for all ports in the select operation. We refer to a select operation without and with optional arguments as scalar and vector select operation, respectively. The syntax for a scalar select operation between two ports is
select(port0, port1) |
The syntax for a vector select operation between two ports is
select(port0, n0, port1, n1) |
An input port is a candidate for selection if and only if it holds that the requested number of tokens is smaller than or equal to the number of tokens that the corresponding output port has committed to produce plus the number of tokens in the fifo. An output port is a candidate for selection if and only if it holds that the requested number of tokens is smaller than or equal to the number of tokens that the corresponding input port has committed to consume minus the number of tokens in the fifo. A select operation returns an integer value that identifies the number of the selected port assuming that the ports are consecutively numbered starting from zero. So the two select operations mentioned above return 0 or 1. Note that a select operation does not terminate, i.e., its execution is suspended, until at least one of the mentioned ports is a candidate for selection.
To illustrate the use of select operations, we extend the Producer-Consumer example to a Producer-Filter-Consumer example. The function of the filter is to multiply the incoming integer values with an integer coefficient and to output the results. We assume that the filter coefficients are produced by another process. The number of coefficients produced by this process nor the rate of production are known. Note that also the time at which they are produced is not known because each process has its own notion of time. In the filter we may read a new coefficient before receiving a new integer value. This is done only if the select operation has selected the port from which the coefficients are read, i.e., when the producer of the coefficients has committed to produce at least one other coefficient. If the select operation has selected the other port then we process the next value. The select operation blocks until it can select a port, i.e., until the other processes have committed to communicate a coefficient or a value.
|
|
Note that if the application designer adds an else clause to the if statement and moves the read and write operation of the values into this clause, then the filter may 'skip' coefficients, i.e., some coefficients may never be used in a multiplication. Such a decision affects the functionality. Therefore it must be made explicit by the application designer.
Finally, note that the selection algorithm that selects a port when there is more than one candidate cannot be controlled by the application designer. The application designer must assume that the selection is a non-deterministic choice between the candidate ports. The reason for this is that in general the status of the ports, i.e., whether a port is a candidate or not, depends on the scheduling of the processes. Vice versa the scheduling of the processes depends on the selection of the ports. The scheduling algorithm of the processes is a design decision taken at a later stage by the system designer based on additional information such as computation and communication delays, resource sharing, timing constraints, etc. Similarly the selection algorithm is a design decision taken by the system designer when mapping an application onto an architecture. These design decision cannot be addressed with YAPI. The application designer has to program the application in such a way that the application is functionally correct independent of the implemented scheduling and selection algorithms.
Normally, a fifo is initialized as follows:
fifo(id("fifo"))
|
This initializes the fifo without specifying the size. Normally, the sizes of fifos have no effect on the functionality of the application, unless they are too small which may cause deadlock. We speak of deadlock when none of the processes can make progress and none of the processes has terminated.
We distinguish between two cases of deadlock. In the first case, all processes are blocked by either a read or a select operation. In that case the fifo sizes do not affect the occurrence of deadlock. Instead you should analyze the communication behavior in your process network since the number of produced tokens is smaller than the number of tokens to be consumed. In the second case, one or more processes are blocked by a write operation. In that case our run-time environment attempts to automatically increase the size of the corresponding fifo such that the write operation can be completed and deadlock is avoided. This will fail if the maximum fifo size is reached. The run-time environment by default allocates 8 kilobytes of memory for each fifo. Hence, the maximum size of a fifo is equal to 8192 bytes divided by the number of bytes of one token.
To support deadlock analysis, fifos can be declared with two optional arguments, namely the minimum size and the maximum size. A fifo with a minimum size of 100 tokens is initialized as follows:
fifo(id("fifo"), 100)
|
In this case the run-time environment may still decide to choose a larger size, but not smaller than 100. Note that the specification of a minimum size is functional because it specifies constraints to prevent deadlock. This is needed if the environment does not automatically increase fifo sizes at run-time. If the minimum size exceeds the default maximum size of the run-time environment, then the maximum size of the run-time environment is changed into the minimum size that has been specified by the application designer.
A fifo with at least 100 tokens and at most 200 tokens is initialized as follows:
fifo(id("fifo"), 100, 200)
|
In this case the run-time environment chooses a fifo size between 100 and 200 tokens. Note that the specification of a maximum size is not functional but that it adds implementation constraints. The application designer can use the maximum fifo size to determine the minimum fifo size at which the process network is free of deadlock. To this end, typically the minimum and maximum size are equal such that the fifo size is fixed. Once the application designer has determined the minimum size, the maximum size can be discarded to obtain maximum implementation freedom.
A fifo can be connected to multiple input ports. In that case, the data that is written into the fifo will be delivered to all input ports, i.e., all input ports receive all the data that is written by the output port. Multicast is automatically implemented if a fifo is given as argument to multiple process or process network constructors. The code fragment below gives an example.
fifo( id("fifo")),
producer( id("producer"), fifo),
consumer1(id("consumer1"), fifo),
consumer2(id("consumer2"), fifo)
|
Similarly, multicast is automatically implemented if you give an input port of a process network as argument to multiple constructors of processes and process networks.
Please note that each output port can be connected to at most one other object. Hence, it is not possible to connect an output port to a fifo and to an output port of the encapsulating process network in order to use data both inside and outside of that process network. In such cases, we recommend to use a special output process that reads data from a multicast fifo and writes it to an output port of the process network. The internal processes and process networks can read from that same multicast fifo.
A select operation (Section 2.2.2) on an output port that is connected to multiple input ports can select that output port if one of the connected input ports requests sufficient tokens. So it has OR-semantics.
The full name of a multicast fifo is extended with an additional index between square brackets in the status and workload tables; see Section 2.3.1 and Section 2.4. Each output and input port pair gets a unique index. The indices are consecutively numbered starting from zero.